想象一下,让你对一串字符串进行编码,使其成为只由0和1构成的序列,你会设计怎样的编码算法?
70年前,在MIT攻读博士学位的哈夫曼构建了一棵二叉树实现了最有效的编码算法。
这棵树名为最优二叉树,也被称为Huffman树。
编码
看到0和1,我们自然就很容易想到二进制数,想到将每一个字母对应一个二进制数。
比如:对于序列"ABCD",可以将A编为0,B编为1,C编为10,D编为11。这样一来,编码后的序列就可以写作"011011"。看起来好像没什么不对。但是…解码的时候呢?前三位"011"是应该被理解成"ABB"还是"AD"呢…?
可以发现,用简单的二进制不等长编码并不能解决我们的问题,究其原因,主要是因为"B"的编码与"D"的编码拥有相同的前缀 (都为"1")。这时,就需要我们引入一个可以避免这种情况的编码方法——前缀编码。
前缀编码
前缀编码是指对字符集进行编码时,要求字符集中任一字符的编码都不是其它字符的编码的前缀。
比如,还是对"ABCD"进行编码,可以将A编为0,B编为10,C编为110,D编为1110,这样一来,就可以有效避免解码时的歧义,从而快速地进行正确的解码。
要实现前缀编码,需要我们引入一棵二叉树。从根节点开始,往左子树走一步就记为0,往右子树走一步就记为1,这样便可以使每一个结点都有其独特的编码串,而每一个叶结点都拥有互不相同的编码前缀(因为路径各不相同)。

Huffman编码
这棵树就是我们苦苦寻找的Huffman树,通过这棵树,我们就可以从根节点开始向下寻找叶结点,从而完成对序列的编码。而在解码时,只需要根据01序列来判断是应该往左子树走还是往右子树走,直到寻找到叶结点,从而获取原序列,完成编码。
现在唯一的问题就是要如何确定每一个字符所在的位置了。不难发现,Huffman编码并不是等长编码,深度越深的叶结点,所编码出来的01序列也就越长。为了实现编码序列的最短化,我们应该将出现次数多的字符放在较浅的叶结点,出现次数少的则反之。
这个所谓的"出现次数",我们一般称为权值,而Huffman树,便是带权路径长度最短的树。
代码实现
基本变量
Huffman树,不论如何还是一棵二叉树,所以结点的结构与普通的二叉树大体相同,只是需要多一个变量来记录权值。
1
2
3
4
5
6
7
| typedef struct Node
{
Type val;
int weight;
Node *left;
Node *right;
} Node, *HTLink;
|
接着记录一些后续可能会用到的变量,变量的输入就在此不多赘述,只是以放后续函数中用到了而不知道含义,故在此先声明一遍。
1
2
3
4
5
6
|
HTLink root;
vector<Type> values;
vector<int> weights;
int val_num;
unordered_map<Type, string> codePair;
|
构造Huffman树
由于我们要将权值较小的结点作为较深的叶结点,所以操作起来可能较为繁琐:
首先记这些结点分别为n1,n2 … nk,其组成一片森林。
然后从中找出两个权值最小的结点,比如这里的n1与n2,将其用一个父结点p1合并,这里p1的权值为n1与n2的和。
然后将n1与n2从森林中删除,将p1加入森林。
重复以上步骤,直到森林中只剩下一棵树,这棵树就是我们的Huffman树。
这样纯理论地讲可能听起来有点抽象,没事, 我们来举个例子。
首先我们有一片森林,每个结点中的数据都是其对应的权值
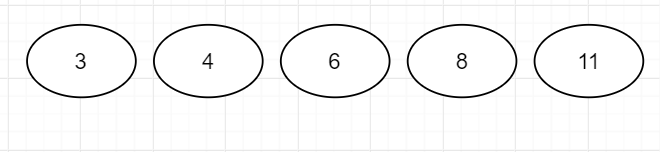
然后取出权值最小的两个结点"3"和"4",将其合并
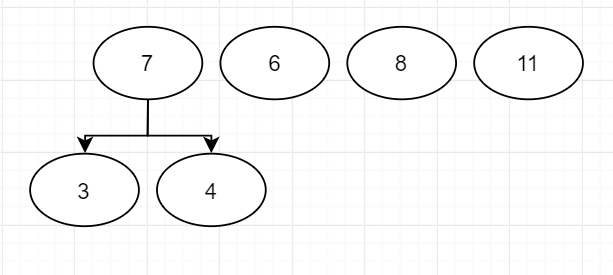
接下来是"6"和"7",继续合并
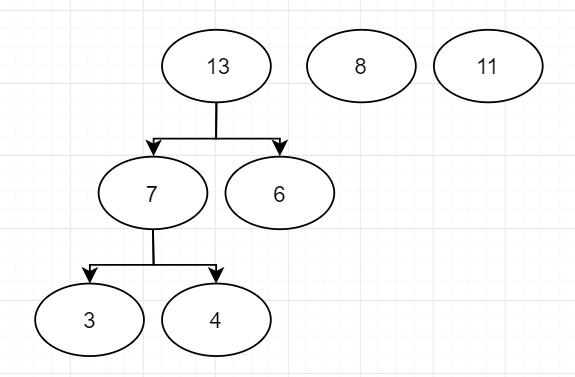
然后是"8"和"11"
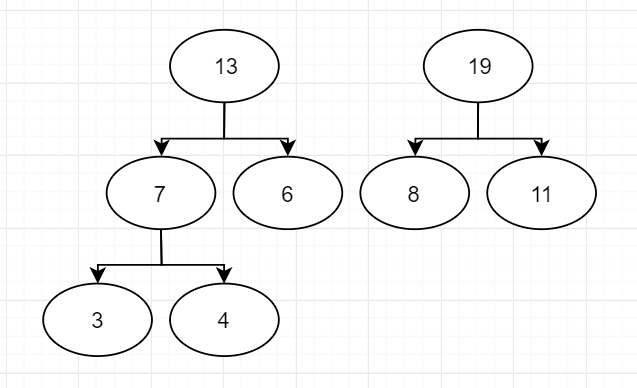
最后一次合并,得到Huffman树
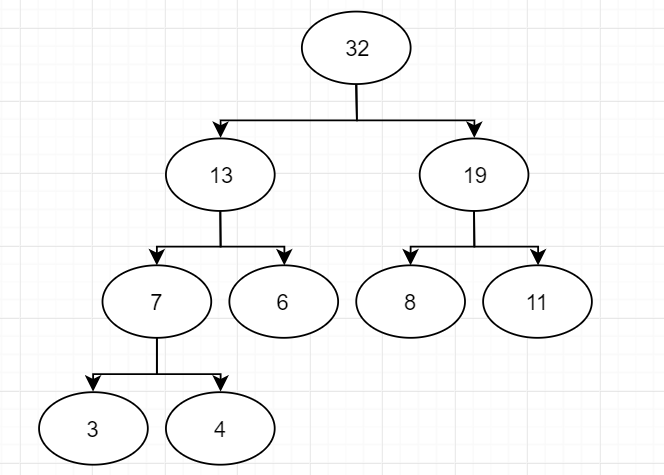
经过这几次合并,我们就实现了将权值越小的结点放在越深的叶结点的过程,同时确保了每一个叶结点可以拥有独特的编码。只要理解了过程,代码就十分容易写出来了:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
| template <class T>
void HuffmanTree<T>::create()
{
int n = val_num;
vector<HTLink> nodes(n);
for (int i = 0; i < n; i++)
{
nodes[i] = (HTLink)malloc(sizeof(Node));
nodes[i]->val = values[i];
nodes[i]->weight = weights[i];
nodes[i]->left = nodes[i]->right = NULL;
}
while (n != 1)
{
HTLink parent = (HTLink)malloc(sizeof(Node));
int minIndex = 0;
for (int i = 1; i < n; i++)
{
if (nodes[i]->weight < nodes[minIndex]->weight)
{
minIndex = i;
}
}
parent->weight = nodes[minIndex]->weight;
parent->left = nodes[minIndex];
nodes.erase(nodes.begin() + minIndex);
minIndex = 0;
for (int i = 1; i < n - 1; i++)
{
if (nodes[i]->weight < nodes[minIndex]->weight)
{
minIndex = i;
}
}
parent->weight += nodes[minIndex]->weight;
parent->right = nodes[minIndex];
nodes.erase(nodes.begin() + minIndex);
nodes.push_back(parent);
n--;
}
root = nodes[0];
}
|
但这里找两个最小结点部分的代码有点繁琐,如果有朋友能想出更优雅的方法记得告诉我~
编码
有了Huffman树,进行编码就不是一件难事了,编码字符的主要过程是通过递归来实现,从根结点开始遍历,递归找到每个字符对应的叶结点:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
template <class T>
void HuffmanTree<T>::code(HTLink cur, string curCode)
{
if (cur->left)
{
code(cur->left, curCode + "0");
}
if (cur->right)
{
code(cur->right, curCode + "1");
}
if (!cur->left && !cur->right)
{
codePair[cur->val] = curCode;
}
}
|
而对于整个字符串序列来说,只需先将每个字符进行编码,然后将字符串进行编码的转换:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| template <class T>
string HuffmanTree<T>::encode(string str)
{
for (int i = 0; i < val_num; i++)
{
codePair[values[i]] = "";
}
code(root);
string encodeStr = "";
for (size_t i = 0; i < str.length(); i++)
{
encodeStr += codePair[str[i]];
}
return encodeStr;
}
|
解码
解码的过程也与上面提到过的方法并无二致:从根结点开始,对于序列中每个字符,若是0则往左子树走,若是1则往右子树走,直到走到叶结点。然后将该叶结点输出,同时指针回到根结点。不断循环以上过程,直到字符序列被遍历完。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| template <class T>
string HuffmanTree<T>::decode(string str)
{
int len = (int)str.length();
int k = 0;
HTLink currLink = root;
string decodeStr = "";
while (k != len)
{
if (currLink->left || currLink->right)
{
if (str[k] == '0')
{
currLink = currLink->left;
k++;
}
else
{
currLink = currLink->right;
k++;
}
}
if (!currLink->left && !currLink->right)
{
decodeStr += currLink->val;
currLink = root;
}
}
return decodeStr;
}
|
以上,就实现了Huffman编码的所有过程,理解了原理后应该不难实现。下面献上完整代码:
完整代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
|
#include <bits/stdc++.h>
using namespace std;
template <class Type>
class HuffmanTree
{
typedef struct Node
{
Type val;
int weight;
Node *left;
Node *right;
} Node, *HTLink;
HTLink root;
vector<Type> values;
vector<int> weights;
int val_num;
unordered_map<Type, string> codePair;
void code(HTLink cur, string curCode = "");
void create();
public:
HuffmanTree(vector<Type> vals, vector<int> weis, int n);
string encode(string str);
string decode(string str);
void showCode();
};
int main()
{
vector<char> vals({'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h'});
vector<int> weis({8, 4, 3, 7, 10, 12, 1, 2});
HuffmanTree<char> ht(vals, weis, 8);
string str = "ghfedcbaaba";
string encodeStr = ht.encode(str);
cout << encodeStr << endl;
cout << ht.decode(encodeStr) << endl;
ht.showCode();
return 0;
}
template <class T>
HuffmanTree<T>::HuffmanTree(vector<T> vals, vector<int> weis, int n)
{
values = vals;
weights = weis;
val_num = n;
root = NULL;
create();
}
template <class T>
void HuffmanTree<T>::create()
{
int n = val_num;
vector<HTLink> nodes(n);
for (int i = 0; i < n; i++)
{
nodes[i] = (HTLink)malloc(sizeof(Node));
nodes[i]->val = values[i];
nodes[i]->weight = weights[i];
nodes[i]->left = nodes[i]->right = NULL;
}
while (n != 1)
{
HTLink parent = (HTLink)malloc(sizeof(Node));
int minIndex = 0;
for (int i = 1; i < n; i++)
{
if (nodes[i]->weight < nodes[minIndex]->weight)
{
minIndex = i;
}
}
parent->weight = nodes[minIndex]->weight;
parent->left = nodes[minIndex];
nodes.erase(nodes.begin() + minIndex);
minIndex = 0;
for (int i = 1; i < n - 1; i++)
{
if (nodes[i]->weight < nodes[minIndex]->weight)
{
minIndex = i;
}
}
parent->weight += nodes[minIndex]->weight;
parent->right = nodes[minIndex];
nodes.erase(nodes.begin() + minIndex);
nodes.push_back(parent);
n--;
}
root = nodes[0];
}
template <class T>
string HuffmanTree<T>::encode(string str)
{
for (int i = 0; i < val_num; i++)
{
codePair[values[i]] = "";
}
code(root);
string encodeStr = "";
for (size_t i = 0; i < str.length(); i++)
{
encodeStr += codePair[str[i]];
}
return encodeStr;
}
template <class T>
void HuffmanTree<T>::code(HTLink cur, string curCode)
{
if (cur->left)
{
code(cur->left, curCode + "0");
}
if (cur->right)
{
code(cur->right, curCode + "1");
}
if (!cur->left && !cur->right)
{
codePair[cur->val] = curCode;
}
}
template <class T>
string HuffmanTree<T>::decode(string str)
{
int len = (int)str.length();
int k = 0;
HTLink currLink = root;
string decodeStr = "";
while (k != len)
{
if (currLink->left || currLink->right)
{
if (str[k] == '0')
{
currLink = currLink->left;
k++;
}
else
{
currLink = currLink->right;
k++;
}
}
if (!currLink->left && !currLink->right)
{
decodeStr += currLink->val;
currLink = root;
}
}
return decodeStr;
}
template <class T>
void HuffmanTree<T>::showCode()
{
for (auto i : codePair)
{
cout << i.first << ':' << i.second << endl;
}
}
|