XML学习笔记#2:DTD
DTD即为Document Type Definition,这是一篇DTD的笔记。
概述
文档类型定义(DTD,Document Type Definition)是一种特殊文档,它规定、约束符合标准通用标示语言(SGML)或SGML子集可扩展标示语言(XML)规则的定义和陈述。
反正也没人看这部分,我就随便从百度百科复制一段了
DTD由元素(Elements)、属性(Attribute)、实体(Entities)与注释(Comments)四部分组成。
但由于其限制上的局限性与使用上的不方便,近年来已逐渐被schema代替。
DTD的文件扩展名为 “.dtd” 。
语法
引用
内部引用
在一个XML文档中引用DTD可分为内部引用 与外部引用 ,很显然,内部引用即将DTD编写在XML文档内,外部引用即引用外部编写好的.dtd文件。
内部引用的基本框架为:
1 |
根元素即为要被解释的部分的根元素。或许听起来有点绕,我们可以看个例子:
1 |
|
这就是一个对<note>元素引用内部DTD的例子。
外部引用
内部引用虽然写起来方便,但是复用性较低。一般情况下我们会选择使用外部DTD,能够使得文档更为清晰,同时也能让DTD文档被多个XML文档所共享。
外部引用又分为私有 与公有 两种。私有的外部引用就是自己编写的,而公有的就是那些官方的、经过认证的引用。
私有外部引用的基本框架为:
1 |
这里的DTD_location即为外部DTD文档的相对或绝对路径,举个例子:
1 |
|
这里就引用了book.dtd中的DTD内容。
而公有的外部DTD引用的框架较之私有的,还需多写一个DTD名称,便于解析器找到该DTD的最新版本。这部分较少使用,稍作了解即可:
1 |
DTD_name的语法
1 | prefix//owner_of_the_DTD//description_of_the_DTD//language_identifier |
第一部分 prefix 可以为 ISO、+、或者 -,分别表示通过批准的 ISO 标准、通过批准的非 ISO 标准、或者未通过批准的非 ISO 标准。
第二部分 owner_of_the_DTD 表示发布该文档的机构。
第三部分 description_of_the_DTD 表示对该文档的简短描述。
第四部分 Language_identifier 则表示其语言版本。
1 | "-//IETF//DTD HTML Strict Level 1//EN" |
提示
内部DTD与外部DTD可以同时组合使用。
元素
DTD中的元素,起到了匹配XML文档中元素的作用,其基本框架为:
1 |
或
1 |
Warning
ELEMENT四个字母必须大写 ,元素内容必须有括号
空元素
空元素即为不包含子元素或子文本的元素,其基本框架为:
1 |
任意元素
即为可以包含任意子内容的元素,基本框架为:
1 |
子内容为文本
即为子内容只能为文本,不能为子元素的元素,但可以是空标记。这里用“#PCDATA”来表示文本内容,PCDATA即为Parsed Character DATA的简写,意为被解析的字符数据。基本框架为:
1 |
子内容为元素
1 |
这其中,“子元素1,子元素2,…”序列为内容模型,其由元素名与标识符构成,有以下六种标识符可选用:
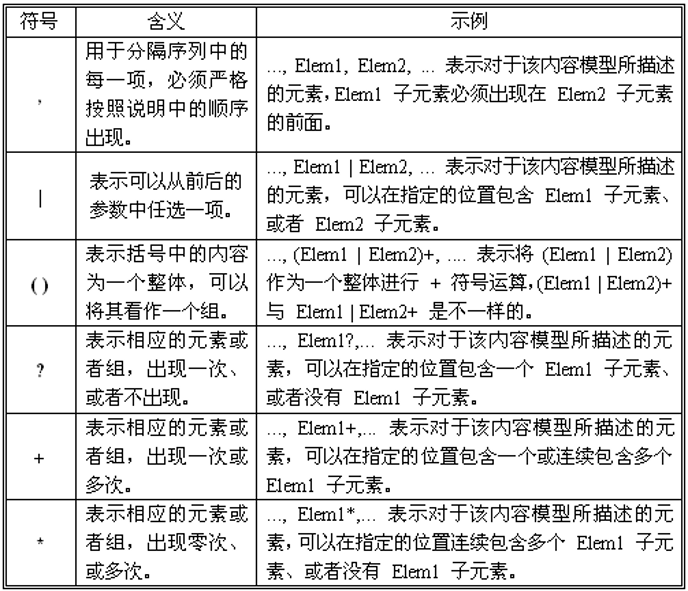
这些标识符可以单独使用也可以组合使用,举个例子:
1 |
这两个都是合法的表达式。但需要注意,在父元素中声明过的子元素,也应该在父元素之后被完整声明,比如:
1 |
子内容有文本与元素
这部分仅作学习,不推荐使用
1 |
之所以把这种形式特别挑出来说,是因为它较为特别。
- 必须将 #PCDATA 放在最前面,必须用*号结尾,必须用“|”分隔。
- 只能约束该标记可以有哪些子标记,不能约束这些子标记出现的次数和顺序。
- 约束条件中不能出现限制符号,如:(#PCDATA|子标记+|子标记*)。
属性
DTD元素的声明框架为:
1 |
对于多个属性,可以选择写在同一个声明,或分为多个声明:
1 |
|
除了元素名与属性名以外的两个概念可能听起来较为抽象,接下来我会一一解释。
属性类型
属性类型有多个可选项,需要注意的是,一律需要大写。
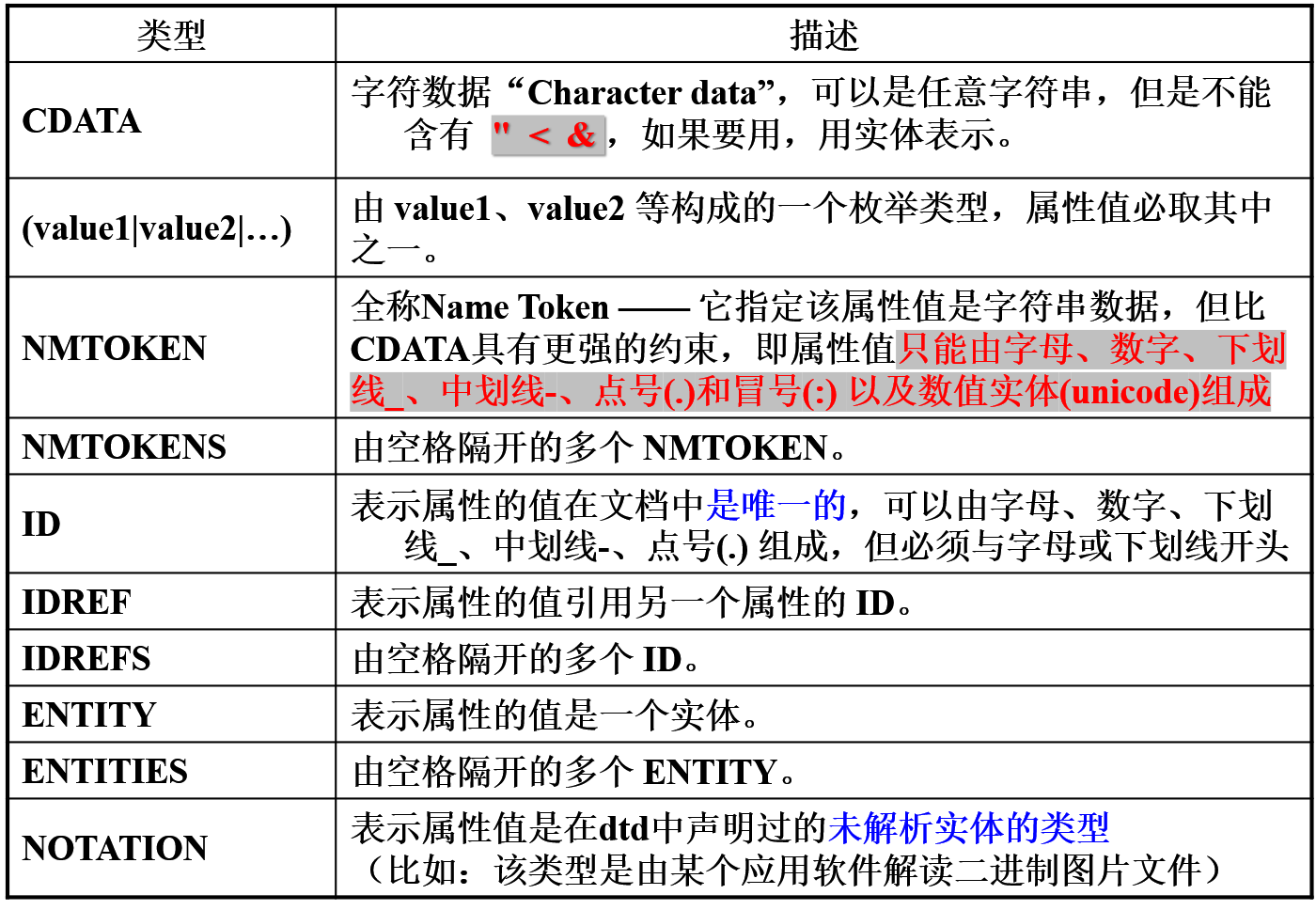
Warning
一个标记的若干属性中,不允许有两个属性的类型都是ID。
属性值
属性值也一样,一律需要大写。

Warning
ID 类型属性的默认情况只能是 #REQUIRED 或 #IMPLIED,不可以是字符串或#FIXED。
举几个例子:
1 |
1 | <memo id="memo-2006-03-14“ keywords="XML XPath XQuery" /> |
1 |
如果在该文档中存在:
1 | <Step id="step1"/> |
则
1 | <StepLink steps="step1 step2"/> |
是正确的。
1 |
1 | <bulletlist icon="bluedot"> |
最后一个例子看不懂也没关系,一会学完实体 后就能明白了。
实体
实体根据出现的位置,可以大体分为两类:在DTD中占位的参数实体 与在XML文档中占位的一般实体 。
参数实体
参数实体只在DTD文档中起作用,不会出现在XML文档的数据中。基本框架为:
1 |
而参数引用的格式为 %实体名 。当然,也可以引用外部的实体,其基本框架为:
1 |
|
Warning
声明实体的时候,“%”与实体名中间有一个空格,而引用实体的时候则不能有空格。
示例:
1 |
|
1 |
|
一般实体
一般实体虽然定义在DTD中,但用于在XML数据中进行占位。之前提到过的“<”、“>”等字符都属于一般实体。其基本框架为:
1 |
参数的引用格式即为**&实体名;** 。
举个例子,在DTD文档中:
1 |
而在XML文档中的
1 | <author>&us;</author> |
就会被解析为
1 | <author>You and me</author> |
数值实体
在XML文档中,可以直接用数值实体引用Unicode编码。
1 | <title>学习XML</title> |
会被解析为
1 | <title>学习XML</title> |
未解析实体
可以在 XML 数据中指明所关联的二进制文件(图片、音频、视频等等),然后由解析器通过调用适当的应用程序对这些文件进行解析。因为解析器本身无法处理这些非 XML 的数据,所以我们将定义这种关联关系的实体称为“未解析实体”。
1 |
|
条件
在DTD中可以使用IGNORE 和INCLUDE 关键字来忽略或包含相应的DTD规则。其基本框架为:
1 |
如果直接使用上述语法,则忽略或包含的DTD规则并不能提供任何价值。因此,需要配合参数实体进行使用。(但依旧用处不大)

提示
IGNORE的优先级比INCLUDE高。